পিছনে তত্ত্ব পি-মূল্য এবং শূন্য হাইপোথিসিস প্রথমে জটিল মনে হতে পারে, কিন্তু ধারণাগুলি বোঝা আপনাকে পরিসংখ্যানের জগতে নেভিগেট করতে সাহায্য করবে। দুর্ভাগ্যবশত, এই পদগুলি প্রায়ই জনপ্রিয় বিজ্ঞানে অপব্যবহার করা হয়, তাই এটি প্রত্যেকের জন্য মূল বিষয়গুলি বোঝার জন্য উপযোগী হবে৷

গণনা করা হচ্ছে পি-একটি মডেলের মান এবং শূন্য হাইপোথিসিস প্রমাণ/অপ্রমাণ করা এমএস এক্সেলের সাথে আশ্চর্যজনকভাবে সহজ। এটি করার দুটি উপায় আছে এবং আমরা তাদের উভয়ই কভার করব। আসুন খনন করা যাক।
নাল হাইপোথিসিস এবং পি-মান
নাল হাইপোথিসিস একটি বিবৃতি, এটি একটি ডিফল্ট অবস্থান হিসাবেও উল্লেখ করা হয়, যা দাবি করে যে পর্যবেক্ষণকৃত ঘটনার মধ্যে সম্পর্ক নেই। এটি দুটি পর্যবেক্ষিত গোষ্ঠীর মধ্যে সমিতিতেও প্রয়োগ করা যেতে পারে। গবেষণার সময়, আপনি এই হাইপোথিসিসটি পরীক্ষা করেন এবং এটিকে অস্বীকার করার চেষ্টা করেন।
উদাহরণস্বরূপ, বলুন যে আপনি একটি বিশেষ ফ্যাড ডায়েটে উল্লেখযোগ্য ফলাফল রয়েছে কিনা তা পর্যবেক্ষণ করতে চান। শূন্য অনুমান, এই ক্ষেত্রে, ডায়েট করার আগে এবং পরে পরীক্ষার বিষয়গুলির ওজনে কোনও উল্লেখযোগ্য পার্থক্য নেই। বিকল্প অনুমান হল যে খাদ্য একটি পার্থক্য করেছে। এটিই গবেষকরা প্রমাণ করার চেষ্টা করবেন।
দ্য পি-মান সেই সম্ভাবনাকে প্রতিনিধিত্ব করে যে পরিসংখ্যানগত সারাংশ পর্যবেক্ষিত মানের সমান বা তার চেয়ে বেশি হবে যখন নাল হাইপোথিসিস একটি নির্দিষ্ট পরিসংখ্যান মডেলের জন্য সত্য। যদিও এটি প্রায়শই দশমিক সংখ্যা হিসাবে প্রকাশ করা হয়, তবে এটি সাধারণত শতাংশ হিসাবে প্রকাশ করা ভাল। উদাহরণস্বরূপ, দ পি-0.1 এর মান 10% হিসাবে উপস্থাপন করা উচিত।
একটি কম পি-মান মানে নাল হাইপোথিসিসের বিরুদ্ধে প্রমাণ শক্তিশালী। এর অর্থ হল আপনার ডেটা উল্লেখযোগ্য। অন্যদিকে, একটি উচ্চ পি-মান মানে হাইপোথিসিসের বিরুদ্ধে কোন শক্তিশালী প্রমাণ নেই। ফ্যাড ডায়েট কাজ করে তা প্রমাণ করার জন্য, গবেষকদের একটি কম খুঁজে বের করতে হবে পি-মান
একটি পরিসংখ্যানগতভাবে তাৎপর্যপূর্ণ ফলাফল হল এমন একটি যা শূন্য অনুমান সত্য হলে ঘটার সম্ভাবনা খুবই কম। তাত্পর্য স্তর গ্রীক অক্ষর আলফা দ্বারা চিহ্নিত করা হয় এবং এটি থেকে বড় হতে হবে পি- পরিসংখ্যানগতভাবে তাৎপর্যপূর্ণ ফলাফলের মান।
ক্ষেত্র বিস্তৃত অনেক গবেষক ব্যবহার পি-তারা যে ডেটা নিয়ে কাজ করছে সে সম্পর্কে আরও ভাল এবং গভীর অন্তর্দৃষ্টি পেতে মান। কিছু বিশিষ্ট ক্ষেত্রের মধ্যে রয়েছে সমাজবিজ্ঞান, ফৌজদারি বিচার, মনোবিজ্ঞান, অর্থ এবং অর্থনীতি।
খুঁজে বের করা পি-এক্সেল 2010-এ মান
আপনি খুঁজে পেতে পারেন পি-টি-টেস্ট ফাংশনের মাধ্যমে বা ডেটা বিশ্লেষণ টুল ব্যবহার করে এমএস এক্সেলে একটি ডেটা সেটের মান। প্রথমত, আমরা টি-টেস্ট ফাংশনটি দেখব। আমরা পাঁচজন কলেজ ছাত্রকে পরীক্ষা করব যারা 30 দিনের ডায়েটে গিয়েছিল। আমরা ডায়েটের আগে এবং পরে তাদের ওজন তুলনা করব।
দ্রষ্টব্য: এই নিবন্ধটির উদ্দেশ্যে, আমরা এটিকে MS Excel 2010 এবং 2016-এ বিভক্ত করব। যদিও ধাপগুলি সাধারণত সমস্ত সংস্করণে প্রযোজ্য হওয়া উচিত, তবে মেনুগুলির বিন্যাস এবং কী নয় তা আলাদা হবে।
টি-টেস্ট ফাংশন
গণনা করতে এই পদক্ষেপগুলি অনুসরণ করুন পি-টি-টেস্ট ফাংশনের সাথে মান।
- টেবিল তৈরি করুন এবং পপুলেট করুন। আমাদের টেবিল এই মত দেখায়:
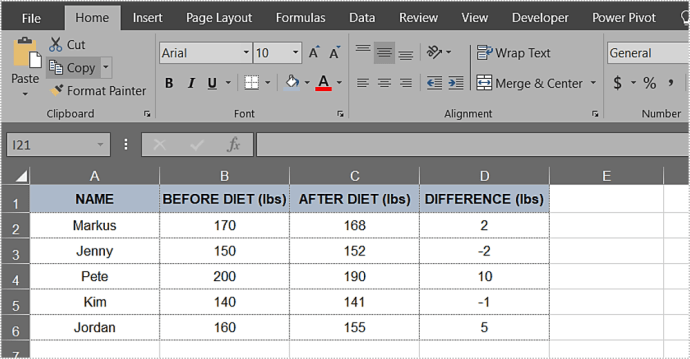
- আপনার টেবিলের বাইরে যে কোনো ঘরে ক্লিক করুন।
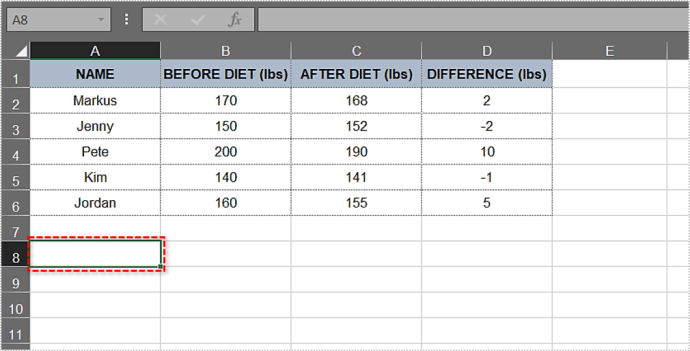
- টাইপ করুন: =T.Test(.
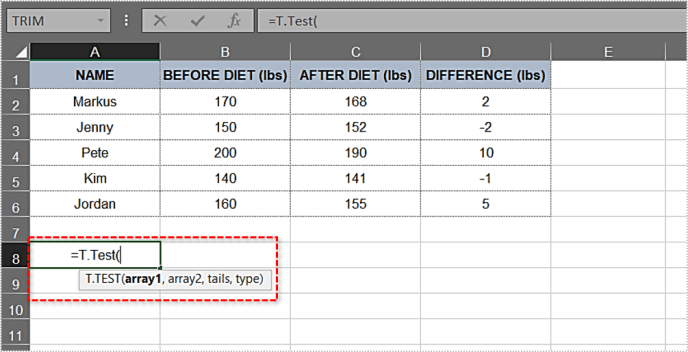
- খোলা বন্ধনীর পরে, প্রথম আর্গুমেন্ট টাইপ করুন। এই উদাহরণে, এটি ডায়েটের আগে কলাম। পরিসীমা B2:B6 হওয়া উচিত। এখন পর্যন্ত, ফাংশনটি এইরকম দেখাচ্ছে: T.Test(B2:B6.
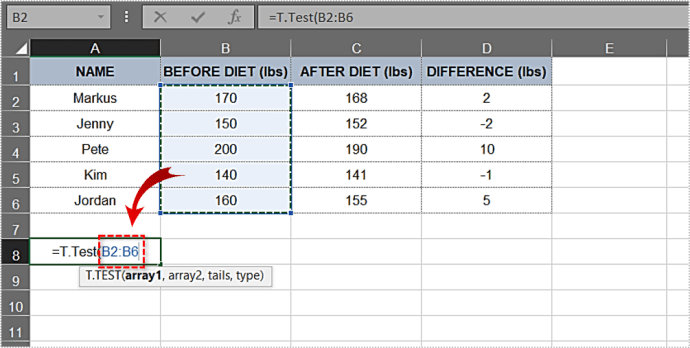
- এর পরে, আমরা দ্বিতীয় আর্গুমেন্টে প্রবেশ করব। আফটার ডায়েট কলাম এবং এর ফলাফল হল আমাদের দ্বিতীয় যুক্তি এবং আমাদের যে পরিসীমা প্রয়োজন তা হল C2:C6। আসুন এটিকে সূত্রে যোগ করি: T.Test(B2:B6,C2:C6.
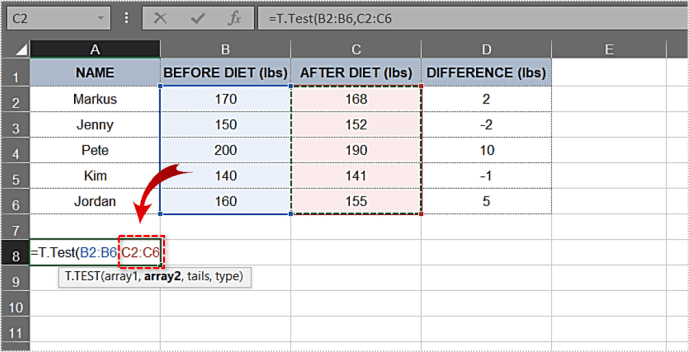
- দ্বিতীয় আর্গুমেন্টের পরে একটি কমা টাইপ করুন এবং এক-টেইলড ডিস্ট্রিবিউশন এবং টু-টেইল্ড ডিস্ট্রিবিউশন বিকল্পগুলি একটি ড্রপ-ডাউন মেনুতে স্বয়ংক্রিয়ভাবে প্রদর্শিত হবে। আসুন প্রথম বেছে নেওয়া যাক - এক-টেইলড ডিস্ট্রিবিউশন। এটিতে ডাবল ক্লিক করুন।
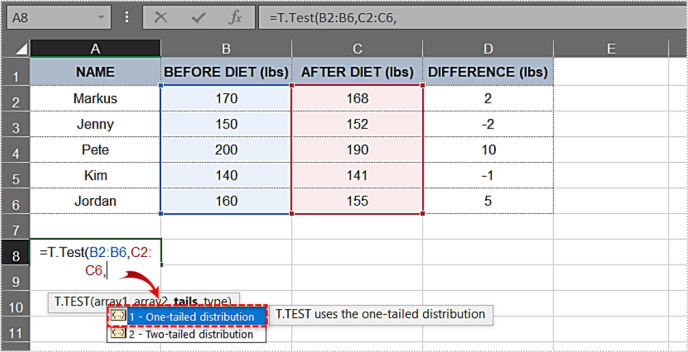
- অন্য কমা টাইপ করুন.
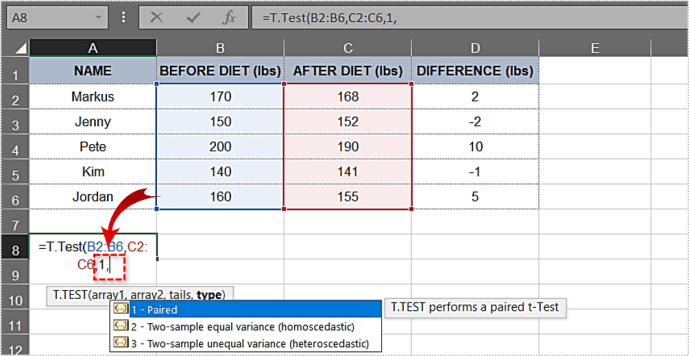
- পরবর্তী ড্রপ-ডাউন মেনুতে জোড়া বিকল্পে ডাবল-ক্লিক করুন।
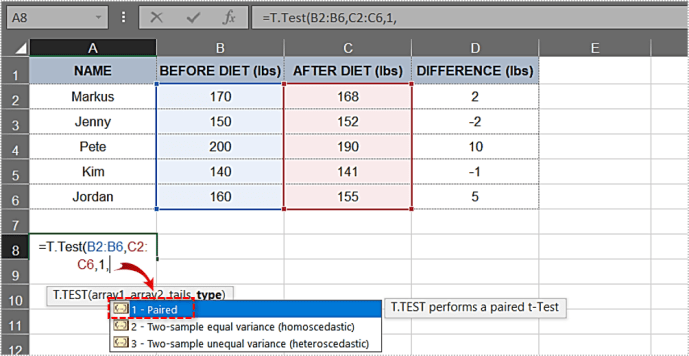
- এখন আপনার কাছে আপনার প্রয়োজনীয় সমস্ত উপাদান রয়েছে, বন্ধনীটি বন্ধ করুন। এই উদাহরণের সূত্রটি এরকম দেখাচ্ছে: =T.Test(B2:B6,C2:C6,1,1)
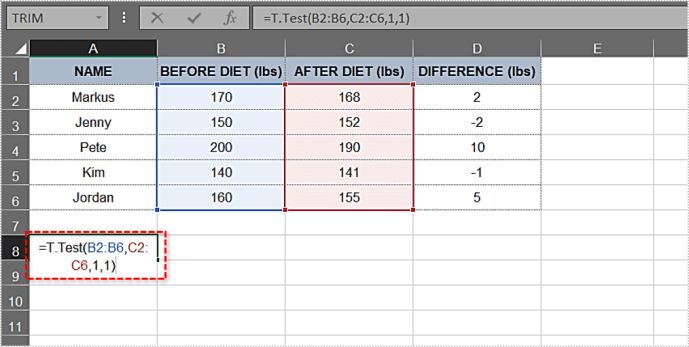
- এন্টার চাপুন. সেলটি প্রদর্শন করবে পি- অবিলম্বে মান। আমাদের ক্ষেত্রে, মান হল 0.133905569 বা 13.3905569%।
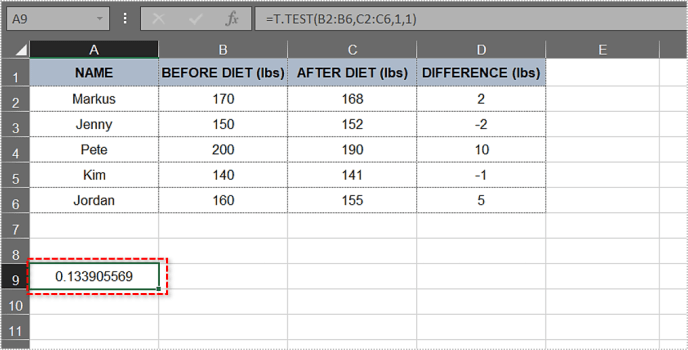










5% এর বেশি হওয়া, এটি পি-মান নাল অনুমানের বিরুদ্ধে শক্তিশালী প্রমাণ প্রদান করে না। আমাদের উদাহরণে, গবেষণা প্রমাণ করেনি যে ডায়েটিং পরীক্ষার বিষয়গুলিকে উল্লেখযোগ্য পরিমাণে ওজন হারাতে সাহায্য করেছে। এর মানে এই নয় যে নাল হাইপোথিসিস সঠিক, শুধুমাত্র এটি এখনও অপ্রমাণিত হয়নি।
ডেটা বিশ্লেষণ রুট
ডেটা বিশ্লেষণ টুল আপনাকে অনেক দুর্দান্ত জিনিস করতে দেয়, সহ পি-মান গণনা। জিনিসগুলি সহজ করতে, আমরা আগের পদ্ধতির মতো একই টেবিল ব্যবহার করব।
এটি কীভাবে করা হয়েছে তা এখানে।
- যেহেতু আমাদের ইতিমধ্যে D কলামে ওজনের পার্থক্য রয়েছে, তাই আমরা পার্থক্য গণনাটি এড়িয়ে যাব। ভবিষ্যতের টেবিলের জন্য, এই সূত্রটি ব্যবহার করুন: ="সেল 1"-"সেল 2"।
- এরপর, প্রধান মেনুতে ডেটা ট্যাবে ক্লিক করুন।
- ডেটা বিশ্লেষণ টুল নির্বাচন করুন।
- তালিকার নিচে স্ক্রোল করুন এবং টি-টেস্ট: পেয়ারড টু স্যাম্পল ফর মিনস বিকল্পে ক্লিক করুন।
- ওকে ক্লিক করুন।
- একটি পপ আপ উইন্ডো প্রদর্শিত হবে. এটি এই মত দেখায়:
- প্রথম পরিসীমা/আর্গুমেন্ট লিখুন। আমাদের উদাহরণে, এটি B2:B6।
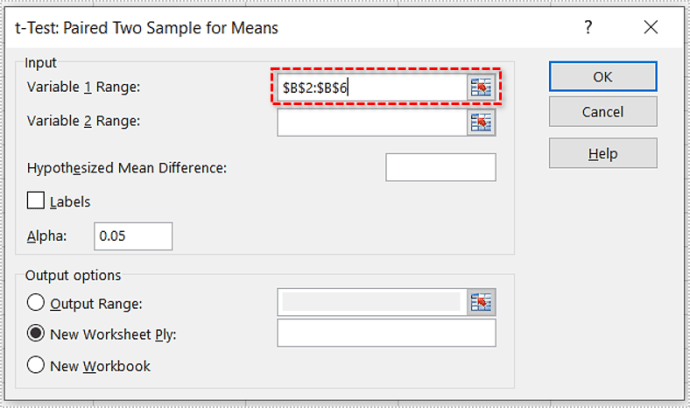
- দ্বিতীয় পরিসীমা/আর্গুমেন্ট লিখুন। এই ক্ষেত্রে, এটি C2:C6।
- আলফা টেক্সট বক্সে ডিফল্ট মান ছেড়ে দিন (এটি 0.05)।
- আউটপুট রেঞ্জ রেডিও বোতামে ক্লিক করুন এবং যেখানে আপনি ফলাফল চান তা বেছে নিন। যদি এটি A8 সেল হয়, তাহলে টাইপ করুন: $A$8৷
- ওকে ক্লিক করুন।
- এক্সেল হিসাব করবে পি- মান এবং অন্যান্য পরামিতি। চূড়ান্ত টেবিল এই মত দেখতে পারে:
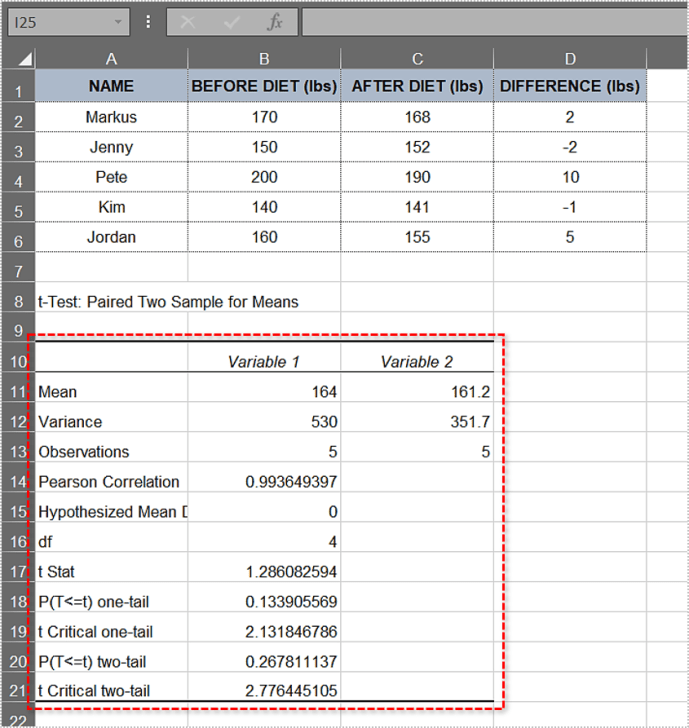











আপনি দেখতে পারেন, এক লেজ পি-মান প্রথম ক্ষেত্রের মতোই - 0.133905569৷ যেহেতু এটি 0.05 এর উপরে, তাই শূন্য অনুমান এই টেবিলের জন্য প্রযোজ্য, এবং এর বিরুদ্ধে প্রমাণ দুর্বল।
খুঁজে বের করা পি-এক্সেল 2016-এ মান
উপরের ধাপের মতই, আসুন এক্সেল 2016-এ পি-মান গণনা করা যাক।
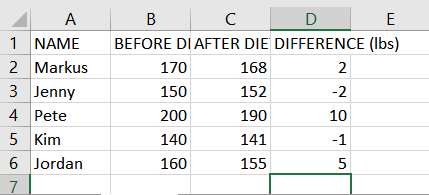
- আমরা উপরের মতো একই উদাহরণ ব্যবহার করব, তাই আপনি যদি অনুসরণ করতে চান তাহলে টেবিল তৈরি করুন।
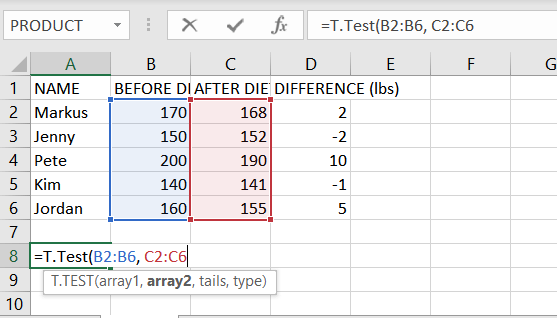
- এখন, সেলে A8, টাইপ =T.Test(B2:B6, C2:C6
- পরবর্তী, কক্ষে A8, পরে একটি কমা লিখুন C6 এবং তারপর নির্বাচন করুন এক-টেইলড ডিস্ট্রিবিউশন.
- তারপর, অন্য কমা লিখুন এবং নির্বাচন করুন জোড়া হয়েছে.
- সমীকরণ এখন হওয়া উচিত =T.Test(B2:B6, C2:C6,1,1).

- অবশেষে, টিপুন প্রবেশ করুন ফলাফল দেখানোর জন্য।
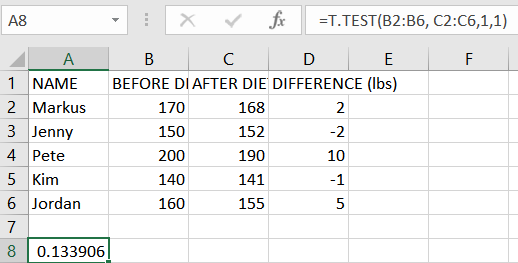




ফলাফল আপনার সেটিংস এবং উপলব্ধ স্ক্রীন স্থান উপর নির্ভর করে কয়েক দশমিক স্থান দ্বারা পরিবর্তিত হতে পারে.
সম্পর্কে জানার জিনিস পি-মান
এখানে সম্পর্কে কিছু দরকারী টিপস আছে পি- এক্সেলে মান গণনা।
- যদি পি-মান 0.05 (5%) এর সমান, আপনার টেবিলের ডেটা উল্লেখযোগ্য। এটি 0.05 (5%) এর কম হলে, আপনার কাছে থাকা ডেটা অত্যন্ত তাৎপর্যপূর্ণ।
- ক্ষেত্রে পি-মান 0.1 (10%) এর বেশি, আপনার টেবিলের ডেটা নগণ্য। যদি এটি 0.05-0.10 রেঞ্জের মধ্যে থাকে, তাহলে আপনার কাছে সামান্য উল্লেখযোগ্য ডেটা আছে।
- আপনি আলফা মান পরিবর্তন করতে পারেন, যদিও সবচেয়ে সাধারণ বিকল্পগুলি হল 0.05 (5%) এবং 0.10 (10%)৷
- আপনার অনুমানের উপর নির্ভর করে দুই-টেইলড টেস্টিং বেছে নেওয়া আরও ভাল পছন্দ হতে পারে। উপরের উদাহরণে, এক-টেইলড টেস্টিং মানে আমরা অন্বেষণ করি যে পরীক্ষার বিষয়গুলি ডায়েটিং করার পরে ওজন হ্রাস করেছে কিনা এবং এটিই আমাদের খুঁজে বের করার প্রয়োজন ছিল। কিন্তু একটি দুই-টেইলড পরীক্ষা তারা পরিসংখ্যানগতভাবে উল্লেখযোগ্য পরিমাণে ওজন অর্জন করেছে কিনা তাও পরীক্ষা করবে।
- দ্য পি-মান ভেরিয়েবল সনাক্ত করতে পারে না। অন্য কথায়, যদি এটি একটি পারস্পরিক সম্পর্ক চিহ্নিত করে তবে এটি এর পিছনের কারণগুলি সনাক্ত করতে পারে না।
দ্য পি- ভ্যালু ডেমিস্টিফাইড
প্রতিটি পরিসংখ্যানবিদকে তার লবণের মূল্য জানতে হবে নাল হাইপোথিসিস পরীক্ষার ইনস এবং আউটস এবং কী পি-মান মানে। এই জ্ঞান অন্যান্য অনেক ক্ষেত্রে গবেষকদের কাজে আসবে।
আপনি কি কখনও গণনা করতে এক্সেল ব্যবহার করেছেন? পি- একটি পরিসংখ্যান মডেলের মান? আপনি কোন পদ্ধতি ব্যবহার করেছেন? আপনি কি এটি গণনা করার অন্য উপায় পছন্দ করেন? আমাদের মন্তব্য বিভাগে জানান.